How Do We Create Our Predictions?
Optimeering’s predictions are produced using a standard generalised infrastructure and prediction methodology, irrespective of the market. Our general approach is summarised as follows.
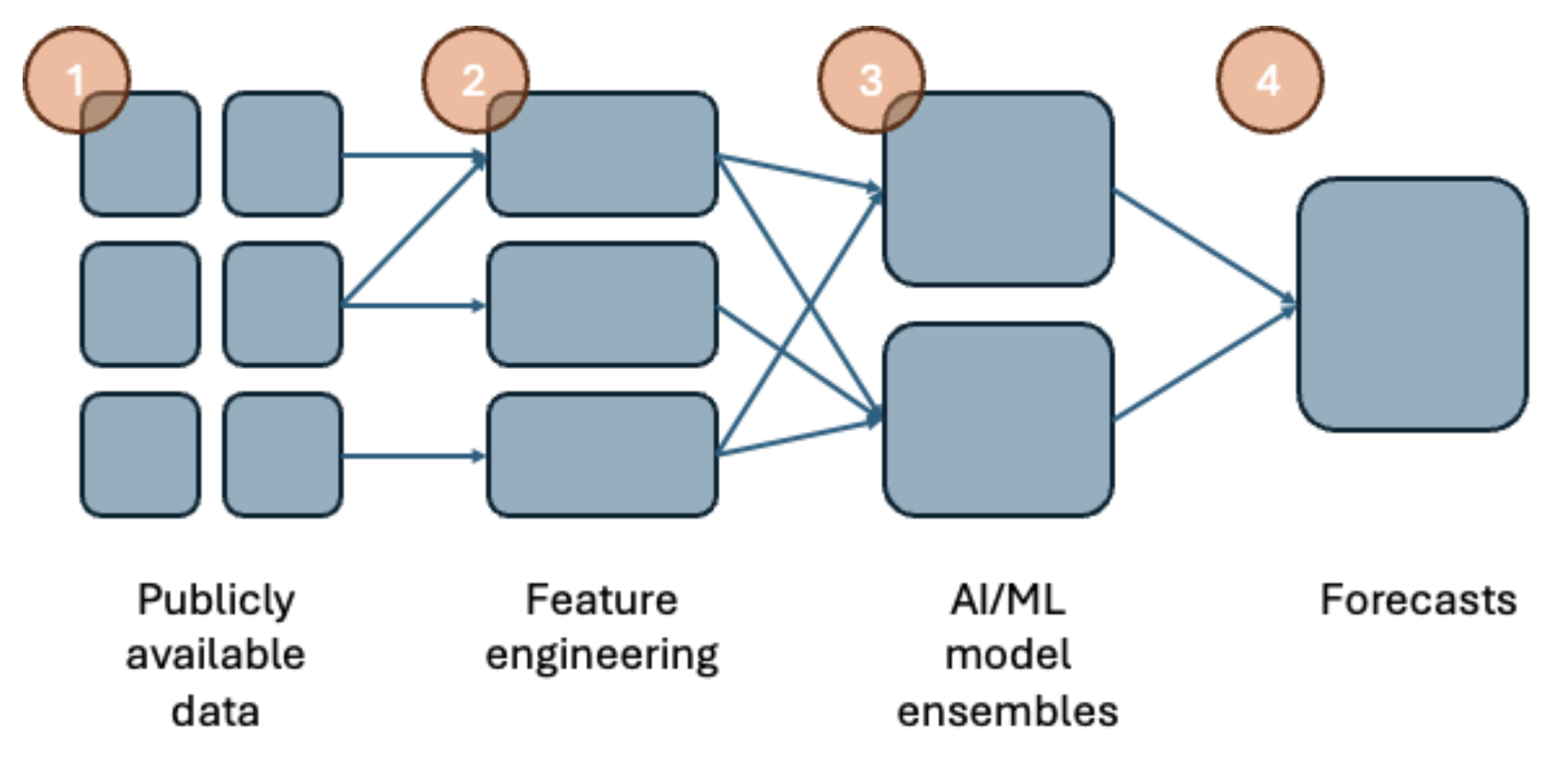
Step 1: Publicly available data
All of our predictions use publicly available data (that is, data that is available to market actors, 3rd party participants, and indeed “members of the public”). This data is either freely available or is made available via payment of reasonable data feed subscription fees.
Example data sources used by Optimeering are:
- Weather data (published by met.no)
- TSO data (ENTSOE transparency platform, as well as on TSO’s own publicly facing data platforms)
- Market data (exchanges such as Nord Pool).
This data is typically obtained by Optimeering via API feeds, processed, cleaned and stored for further use.
Step 2: Feature engineering
The data is automatically analysed, processed and combined into specific model features in-code. These features have been developed by Optimeering based on our insight and understanding of how the power markets work, how they are cleared, and what drives the outcomes (prices, volumes etc). The features we develop are a big part of our “secret sauce” and are important in ensuring the quality of our predictions.
Our features are prepared both on-the-fly and pre-calculated and stored, depending on the computational and data requirements of each feature, before being made available to our prediction models.
Step 3: AI/ML model ensembles
All our predictions are generated using AI and ML (machine learning) modelling. We typically use “model ensembles” - that is, collections of models in series and parallel. Each model takes in features to generate an output, before feeding these to a subsequent model in the ensemble.
An example of this might be a model that processes wind-based features to produce a wind imbalance prediction for a given price area, which is then fed into a subsequent imbalance price prediction model.
Ultimately, each model ensemble will produce a price or volume prediction for the secured market and time interval.
As our models are AI/ML models, specific model instances are trained (or “fitted”) using historical data from the past several years. We undertake a comprehensive model parameter tuning and pruning process to ensure that we do not overfit, and that our model architecture and structure is designed to be as accurate as possible.
Step 4: Predictions
The model ensembles are run on live data (more specifically, on feature data) either at regular time intervals (e.g. every 15 minutes) or when new data (and hence updated features) are made available to the models.
The outputs from our model ensembles are combined to produce the specific market prediction provided by Optimeering. Some predictions use a set of rules to perform this, for others we use an AI/ ML “meta model” to learn how to best combine the ensemble predictions based on past data and to then perform the combination process.